Kiss-catalog
Presenting a new (small) project.
Kiss-Catalog!
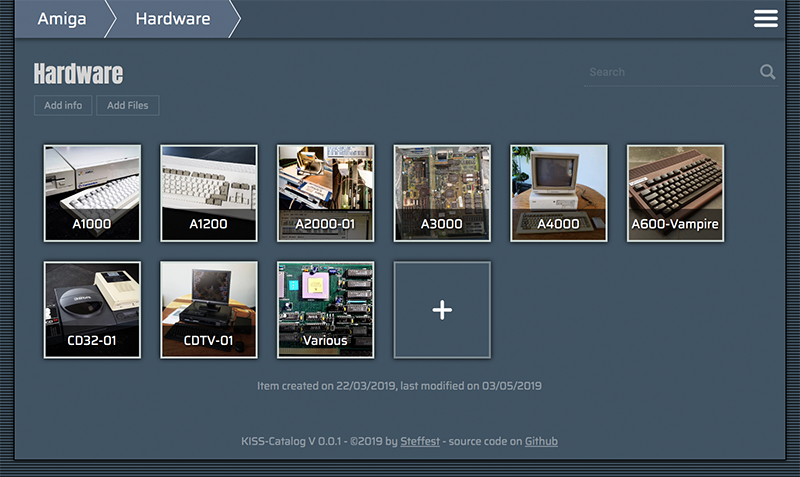
It's an insanely simple Catalog System to keep track of your collections.
Some context
People who know me know I'm a bit of a collector.
Ok, some call it "hoarder" but I call it collector.
The difference between a collector and a hoarder is that the former knows what he has and keeps everything in good shape.
Still ... my retro computer collection is growing towards a point where I don't know exactly what I have anymore, or - more frequently - where I put it.
Questions like "I know I have this Amiga accelerator card, but ... where the heck is it?" need answers.
There's a ton of software already out there to help with that but I wanted something super-super-simple and with some very specific features.
As experience taught me: If it's too hard to maintain, it won't be.
Goals
- Simple simple simple to maintain
- Accessible from anywhere (which in my case always translates to "web based")
- Everything should be searchable/browsable to quickly locate an item or to quickly show some overviews
When you start googling or asking around you get responses like. "Oh, an SQL database is what you need" or "There's an app for that, I use Collectorz or Numento"
No, no, no, nonono - been there done that. This is not my first attempt at cataloguing.
All other attempts stranded in
- OR complex systems that took forever to maintain
- OR external platforms that ceased to exist...
Did I mention it should be simple?
So: no database, no third party software, no fancy stuff.
Plain files and folders, plain JPG and .TXT files.
The concept:
You structure your collection in folders. Each folder can contain files and subfolders that further describe your item. Info is stored in plain text files. Images are stored in .jpg or .png. Any other file you add is just regarded as "file".
Then, a script is run that pulls all these files into data-structure.
This .json file is used to display a webinterface with browse and search features.
When you edit/add content from the webinterface, the local files are changed.
The "database" is always being generated from the local files. This means your data is your data: it lives in your folder as plain text files, completely outside Kiss-catalog.
If you stop using Kiss-catalog and delete it from your system, your hard cataloguing-work is not lost.
The main info file is called "info.txt"
The main image of an item is called "main.jpg"
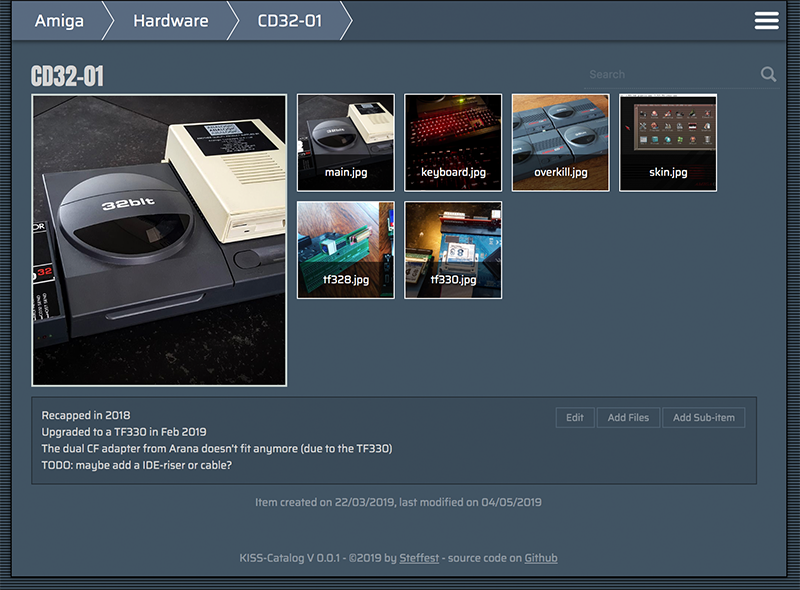
If you want to display your collection on the web, simply put all your static files on a webhost.
No database or serverside processing needed.
That's it!
Everything runs
- BOTH locally and remote
- BOTH as a static website and a somewhat full-featured dynamic Content-Management System.
There's a small demo collection at http://www.stef.be/collector/amiga/ (read only)
Still starting to populate it, first I have to FIND all stuff :-)
And of course: Open Source and everything.
It's made for personal use, but you're free to give it a go. Feature requests are welcome.
It runs one Node but if that doesn't ring any bells there are also pre-compiled binaries for Windows, Mac and Linux
Drawbacks
These "design" decisions have some drawbacks:
- Flat file "databases" only go that far, if your collections is reaching like a 100.000 items, Kiss-catalog is not for you
- Because everything is generated from your local files, this might get slow with large collections. Also there's no image processing (yet) so all images are displayed "as is" : if you fill everything with 4K images, loading will be slow.
- If I ever want to add features like "private files or folders" or whatever - I will probably have to settle for some naming scheme.
- Likewise for "calculated" fields like prices etc. some convention will be necessary.
The Philosophy
I've been pondering the last few months (years?) over something I call "sustainable software"
It's probably not a new concept but that's what I call it in my head.
Basically it means that a developer should write software that is as simple as possible for the job.
Not because simplicity is a goal in itself, but because simple software lasts longer.
It's easier to maintain, consumes less resources, runs faster, ...
Developers should write software to last.
It's all too easy to quickly throw something together using the funky libraries and frameworks that today are considered "modern". Before you know it you're lugging along a staggering dependency tree and rely on a multitude of online services to get your thing built/compiled/deployed.
Yes, you're the cool kid on the block, but how will it look in a few years? Will it still build/compile/deploy?
If it's a fairly simple web-app, do you really need that 2 MB javascript package, 7000 lines of CSS and 4MB initial page load? Maybe ...
In this project "sustainable software" means:
- no exotic or platform dependent file formats. plain text RULEZ
- no external (web)platforms: it's the only way to make sure your data is still there in a few years time.
- no code dependencies. again: it's the only way to make sure your system still runs in a few years time.
- platform independent. everything should run on - and be maintainable from - whatever device you use.
Anyway - that's food for maybe another blog post - don't get me started on frontend builds that pull in ONE MILLION packages and takes 20 minutes and 8gig to build ...
For now: Happy Cataloguing!
Tags: Commodore Amiga, in English, ProgrammingGeef je reactie (0)